
알고리즘공부는 어렵지만 공부할수록 프로그래밍 실력이 늘고 있다는 것을 느끼게 됩니다. 저는 C++를 그렇게 잘 알지 못했고 그 와중에 알고리즘공부를 하느라 힘들었습니다. 하나하나 C++ 개념들을 배워갔지만 모르는 것은 역시나 많았습니다. 삽질한 내용들을 토대로 정리해서 알고리즘 초보자로써 알고리즘 문제를 풀 때 좋은 팁을 모아모아 초보자라도 "이것만" 알면 C++를 사용해서 많은 문제들을 풀 수 있는 상식들을 공유합니다.
정렬 많이 씁니다.
연산순서가 중요합니다.
int a = (int) p * 100 이것과 (int) 100 * p 는 다릅니다.
입력을 주다가 안주는 것은 이렇게 EOF로 거르면 됩니다.
지역변수로 계속 배열을 만드는 것보다는 전역변수를 쓰는게 좋습니다.
- 백준 ntopia님의 답변.
실수형은 웬만하면 정수형으로 받아야 합니다. 이렇게 말이죠.
알고리즘 template
기본적인 cin, cout은 좀 느립니다. 시간초과가 뜨는 문제를 저렇게 ios, cin.tie 등으로 셋팅해 놓으면 시간을 줄일 수 있습니다.하지만 저걸 쓸 때는 iostream과 scanf 등의 stdio에 있는 것들을 혼용해서 쓰면 안됩니다. 저 ios_base::sync_with_stdio(false); 라는 것은 stdio의 다른 입출력함수들과 iostream의 입출력함수들과의 동기화를 푼다는 것이기 때문에 순서가 뒤죽박죽이 될 수 있어서 오류가 날 수도 있습니다.
그 외에도 typedef를 하게 되면 편하게 쓸 수 있습니다. 복붙해서 쓰시면 됩니다.
다닥다닥 붙여있는 입력처리
한개의 digit을 받는다라는 뜻으로 %1d를 씁니다.
*%는 출력형식을 지정하는 것을 뜻합니다.
소수점 출력 및 포맷설정
cout을 사용하면 precision을 걸면 되고 printf를 할경우에는 저렇게 .6으로 셋팅을 해줍니다. 02로 표기하고 싶을 때 저렇게 하면 됩니다.
*%는 출력형식을 지정하는 것을 뜻합니다. lf는 double, f는 float를 뜻하며 double이 더 많은 수를 표기할 수 있습니다.
lower_bound와 uppper_bound
전자는 0번째 배열의 원소부터 찾아서 어떠한 값의 이상이 되는 위치를 반환하며 후자는 마지막 원소부터 찾았을 때 그 값이 시작되기 전의 위치를 반환합니다. 반환되는 값은 이터레이터이기 때문에 v.begin()을 빼주어서 int형으로 몇번째인지를 파악할 수 있습니다.
map
map과 unordered map입니다. key와 value로 이루어져 있는 집합입니다. STL의 map은 R-B트리로 이루어져 있어 삽입, 삭제, 검색 시에 동일한 시간복잡도인 O(lgN)를 지닙니다. 반면 unordered_map은 해시테이블로 이루어져 있어 탐색에 있어 O(1)의 시간복잡도를 지닙니다. 그러나 데이타가 작은 경우에는 map이 더 좋습니다. 데이타가 큰 경우에는 unordered_map이 더 좋습니다.
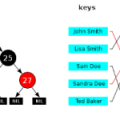
데이타가 클 때 검색의 경우에는 unordered map을 사용하고 순차적인 접근에 map을 사용하는 것이 좋습니다.
* 이와 비슷한 것이 Set입니다. Set은 중복된 데이터가 없는 집합을 말합니다.
queue
다익스트라 알고리즘이나 여러 알고리즘에 쓰이는 자료구조 입니다. 가장 먼저 집어 넣은 데이타가 먼저 나오는 FIFO구조로 저장됩니다만 STL의 priority_queue는 queue + 우선순위먼저 나오는 que입니다.
struct 구성하기
비교연산자를 쓸 수 있습니다. 저렇게 operator를 걸면 됩니다.
만약 중복된 것들을 파악하고 지워야 한다면?
이렇게 unique와 erase를 쓰면 됩니다. s(3, 1)은 1이라는 원소 3를 가지는 벡터로 초기화 한다는 뜻입니다.
세그먼트 트리를 만들 때
트리구조를 만들 때 얼마나 많은 트리가 생성될 것인가. 고민하게 됩니다. 가장 큰 값의 범위에 log를 먹이고 이를 토대로 treeSize를 계산 합니다. 예를 들면 4의 경우, h = 2가 되고 treeSize = 8이 됩니다.
반올림
형변환은 중요합니다. 반올림을 하실 때 double로 나누면서 round메서드를 실행시키고 int로 형변환을 해주면 됩니다.
배열
또한, vector의 경우 v.size(), list의 경우, sizeof(arr)/sizeof(arr[0]);로 사이즈를 알 수 있습니다.
아스키코드
많이 쓰이는 아스키코드입니다.
0 : null입니다.
65 : A입니다.
97 : a입니다.
이렇게 char 형을 int형으로 바꿀 수 있습니다.
*라이블로그 코드를 참고했습니다.
https://kks227.blog.me/220804885235?Redirect=Log&from=postView
문자열 입력과 출력
마지막 문자는 끝을 나타내는 null이 되므로
초기화할 때 문자의 크기보다 +1을 해줘야 합니다.
메모이제이션시 double 형
메모이제이션을 할 때 double형은 ret == -0.5이런식으로 하면 안됩니다. 부동소수점이라서 정확한 0.5가 아니기 때문입니다.
ret <= -0.5로 잡아야 합니다.
많이 나오는 알고리즘
다익스트라
다익스트라는 현재로부터 최단거리를 뽑아 낼 때 씁니다. 현재로부터 그 지점까지의 거리를 비교하면서 dist를 업데이트하고. 그럴 때 priority queue를 이용하여 항상 "최소값"부터 비교하는게 특징입니다.
벨만 포드 알고리즘
이런이런.. 아쉽게도 경로에 음수가 있다면 다익스트라처럼 한번씩만 방문하면 되지 않습니다. 모든 경로를 탐색해줘야 한다. 왜냐면 음수로 인해 경로가 업데이트가 되기 마련이기 때문이죠.
피보나치수열, 빠른 거듭제곱, 행렬계산
이항계수
에라토스테네스의 채
최대공약수와 최소공배수
KMP
접미사
TSP
상호배타적 집합, disjoint Set
'공부 > 정보' 카테고리의 다른 글
| Jupyter Notebook token이 없는 문제 (0) | 2018.12.31 |
|---|
